Wenn sie sich mit dem Aufbau von Computerspeicher auskennen, dann wird dieses Kapitel vielleicht nicht so interessant sein. Wenn sie hingegen bisher nur mit anderen Programmiersprachen gearbeitet haben, oder vielleicht nie programmiert haben, dann ist dieses Kapitel für sie. Die anderen können es einfach auslassen und sofort mit dem nächsten weiter machen. Wenn beim Betrieb von Forth etwas nicht klar sein sollte, was den Speicher betrifft, dann kann man sich dieses Kapitel hier immer noch durchlesen.
Speicherplatz eines Computers ist der Bereich, in dem Daten und Programme liegen, mit denen der Computer arbeitet. Dabei ist dieser Platz nicht einem leeren Blatt Papier vergleichbar, auf dem dann Programme oder Daten geschrieben werden können, sondern eher einer Liste von (meist sehr kleinen) Zetteln, auf denen dann die Daten oder die Programme stehen. Um auf diese 'Zettel' zugreifen zu können, sind sie nummeriert. Die Größe eines dieser Zettel hängt davon ab, wieviel an Daten der eigentliche Computer 'auf ein Mal' einlesen oder schreiben kann. Bei modernen Computern ist das in der Regel ein Bereich, der acht Bit groß ist. Diese Zusammenfassung von Bits nennt man ein Byte, wobei ein Bit eine Informationseinheit ist, die nur die Werte 0 und 1 annehmen kann.
Man kann die Bits in einem Byte als Zahl im Zweiersystem verstehen und dann kann man in einem Byte Zahlwerte zwischen 0 und 255 darstellen. Auf diese Darstellung wird später noch genauer eingegangen. Hier reicht es zu wissen, dass der Computerspeicher quasi aus nummerierten Zetteln besteht, auf denen eine beliebige Zahl zwischen 0 und 255 stehen kann.

Die aufsteigenden Nummern der 'Zettel', ab hier werde ich sie nur noch Bytes nennen, nennt man auch Adresse. Diese Adressen sind in Forth wichtig, denn unter genau dieser Bezeichnung wird in Forth auf den Computerspeicher zugegriffen.
Greift Forth denn nun auch auf die einzelnen Bytes des Speichers zu? Ja und Nein, müsste die Antwort lauten, denn Forth kann auf einzelne Bytes des Speichers zugreifen, aber in der Regel macht Forth das nicht. Der Grund dafür ist einfach: Der Zahlbereich von 0 bis 255 ist ja nun wirklich nicht das, was die Herzen höher schlagen lässt.
In traditionellen Forth-Systemen hatte es sich druchgesetzt zwei Bytes als Einheit für eine Zahl zu nehmen. Damit konnten (vorzeichenlos) Zahlen zwischen 0 und 65535 dargestellt werden und man kann schon eine riesige Menge damit anfangen, wenn man sich vorher ein paar Überlegungen macht. Außerdem kannten diese Systeme auch noch 'doppelt' große Zahlen, die 4 Bytes beanspruchten und damit Zahlen zwischen 0 und 4294967295 darstellen konnten.
Heutzutage gibt es de facto keine Computer mehr, die mit so kleinen Zahlwerten arbeiten. Die 'normale' Zugriffsgröße beträgt 32 Bit, bei manchen Rechnern auch 64 Bit. Forth ist mit dieser Entwicklung mitgewachsen und kann nun auch vier Byte (=32 Bit) für normale und acht Byte (=64 Bit) für 'doppelte' Zahlen verwenden. Um das Problem zu umgehen, wie groß denn nun eine Zahl in Forth tatsächlich ist, hat man sich in der Forth-Welt darauf geeinigt, von Zellen zu sprechen. Eine normale Zahl beansprucht dann ein und eine doppelte Zahl zwei Zellen. Wieviele Byte eine Zelle tatsächlich enthält braucht uns hier erst mal nicht zu interessieren, vor allem auch deswegen, weil moderne Forth-Systeme diese Information gut zu kapseln wissen.
Wie greift Forth denn nun auf den Speicher zu. Dazu gibt es zwei
Wörter, die allerdings in den unterschiedlichsten Varianten
existieren, wovon hier nur die beiden elementarsten beschrieben
werden sollen. Der erste ist ! (genannt: Store). Dieses
Wort bekommt einen Wert und eine Adresse übergeben und speichert
dann den Wert ab dieser Adresse. ! kümmert sich selber
darum, wie groß dabei eine Zahl ist und wieviele Bytes er nehmen
muss, um eine Zelle zu bilden, welche diese Zahl aufnehmen kann. Für
den Fall, dass eine Zelle vier Bytes 'lang' ist, ist das Ganze im
folgenden Bild dargestellt.
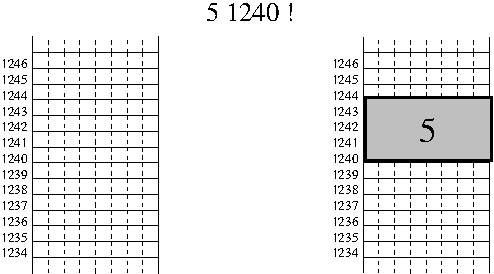
Das Gegenwort ist @ (genannt: Fetch -- und diese
Bezeichnung ist deutlich älter als die später entstandene
Bezeichnung At, die sich heutzutage für dieses Zeichen eingebürgert
hat.) Er bekommt nur eine Adresse übergeben und liest den Zahlwert,
der ab dieser Adresse im Computerspeicher steht aus und legt ihn auf
den Stack.
Viele Begriffe, die nun genannt werden, sind für sie vielleicht erst mal unerklärlich oder erscheinen ihnen fremd. Lassen sie sich nicht dadurch stören. Im Verlauf dieses Tutoriums werden sie ihnen klar werden. Ich werde in einem späteren Kapitel auch noch mal darauf zurück kommen.
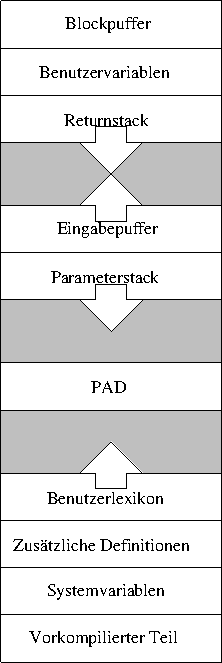
Zuunterst liegt der vorkompilierte Teil. Das sind die Worte von Forth, die Forth kennt, wenn sie es starten. Darüber liegen die Systemvariablen, das sind Variablen, die steuern, wie Forth arbeitet. Hier wird zum Beispiel abgelegt, ob eine Zelle 2 oder 4 Byte lang ist. Danach kommen zusätzliche Definitionen, das sind Worte, die unter Umständen nach dem Start von Forth noch nachgeladen werden. Bei dem hier verwendeten System lina zum Beispiel sind das eine ganze Reihe von Hilfswörtern, welche die Arbeit mit lina vereinfachen und verbessern.
Dann kommt das Benutzerlexikon. Das ist der Teil von Forth,
den sie hinzugefügt haben. Haben sie zum Beispiel im letzten Kapitel
stern definiert, dann wird die Definition in diesen
Bereich kompiliert. Oberhalb des Benutzerlexikons ist erst einmal
ein gewisser Speicherbereich frei, dann kommt ein Speicherbereich,
den Forth nutzt, um Ausgaben vorzubereiten. Dieser Bereich heißt PAD
und hat keinen festen Ort, er liegt nur üblicherweise etwas oberhalb
des Endes vom Benutzerlexikon.
Noch weiter oberhalb kommt der Stack, den sie schon kennen gelernt haben. Hier werden die Zahlen gelagert, die 'auf dem Stack' liegen. Der Stack wächst 'nach unten', also in Richtung kleinerer Adressen. Unittelbar über dem Parameterstack liegt der Eingabepuffer. Hier legt Forth Eingaben erst mal ab, bevor sie verarbeitet werden.
Ganz oben im Speicher liegt dann ein weiterer Stack, der sogenannte Returnstack. Dieser Stack wird später noch erklärt, entspricht aber, für diejenigen, die sich mit den Interna eines Computers auskennen, dem normalen Stack des Prozessors. Oberhalb davon liegen die Variablen, die der Benutzer verändern kann. Dazu zählt zum Beispiel eine Variable, die angibt, zu welcher Zahlenbasis die Ein- und Ausgaben erfolgen sollen. Und darüber liegt dann der Blockpuffer, der für den Austausch der Daten mit Festplattenspeicher und ähnliches vorgesehen ist.
Bevor nun irgendjemand kommt und mich daauf hinweist, dass bei heutigen Computern der Speicher längst nicht mehr so aussieht, wie hier dargestellt, möchte ich klar stellen, dass ich das weiß. Dennoch ist diese Sichtweise auf Computerspeicher sinnvoll und hilfreich bei den folgenden Betrachtungen. Die Details moderner Speichernutzung sind im Weiteren nicht von Interesse.