Dieses Kapitel ist vollkommen überholt. Alles was hier beschrieben wird, stimmt nicht, hat mit der Wahrheit nichts zu tun!
Was soll das denn? Werden sie sich fragen. Wenn der doch schon zum Beginn des Kapitel weiß, dass alles, was nun kommt veraltet ist, wieso schreibt er es denn dann nicht direkt richtig hin?
Der Grund dafür ist einfach. Im folgenden Kapitel wird beschrieben, wie Forth funktioniert. Das Problem dabei ist, dass es mittlerweile jede Menge Implementationen gibt, bei denen die Interna anders organisiert sind. Da ich nicht jede Implementation kenne und daher auch nicht jede beschreiben kann, gebe ich hier eine Beschreibung eines 'alten' Forth. Grundsätzlich arbeiten auch neue Forth-System ähnlich, aber wie gesagt, der exakte Aufbau wird von Forth zu Forth unterschiedlich sein.
Normalerweise, wenn sie Forth gestartet haben, passiert erst mal nichts (Hat ja in unserer schnelllebigen Zeit durchaus auch mal seine Vorteile). Dann geben sie etwas ein und drücken dann die Returntaste. Danach beginnt Forth zu arbeiten und wenn es mit der Arbeit fertig ist, gibt es ein 'ok' aus und wartet dann wieder. Zwischen ihrem Druck auf die Return-taste und dem 'ok' passiert natürlich eine ganze Menge und das soll nun erklärt werden.
Das was die Aktion nach ihrem Druck auf die Return-taste ausführt
ist natürlich wieder ein Wort und zwar: INTERPRET.
INTERPRET geht dabei folgendermßen vor: Als allererstes
wird das erste Wort aus der Eingabe vom Rest getrennt.
Dann versucht INTERPRET das Wort im Wörterbuch zu
finden. Das geschieht mit einem weiteren Wort, dem Wort
FIND. Dieses Wort bekommt ein Wort übergeben und
sucht dieses Wort im Wörterbuch. Wenn es das Wort findet, legt es
seine Adresse und ein Flag mit dem Wert 'wahr' auf den Stack, wenn
es das Wort nicht findet, gibt es das Wort und das Flag 'falsch'
zurück. Damit kann dann INTERPRET entscheiden, ob es
das Wort ausführen kann (gefunden) oder versuchen soll, es als Zahl
zu behandeln (nicht gefunden).
Es gibt ein ähnliches Wort, ' (einfaches oberes
Anführungszeichen, genannt: 'Tick', das sehr ähnlich arbeitet,
allerdings gibt es kein Flag zurück. Wird das übergebene Wort im
Wörterbuch gefunden, dann wird seine Adresse zurück gegeben,
ansonsten führt ' einfach ABORT" aus und
gibt eine Fragezeichen aus.
Sie erinnern sich noch an das Wort stern, dass im
dritten Kapitel definiert wurde? Wenn nicht, hier ist noch mal die
Definition:
: stern 42 EMIT ;[RETURN] ok
Wenn sie dieses Wort neu definieren (oder noch definiert haben), können sie eingeben:
' stern ok
Wenn sie sich nun den Stack ansehen, liegt die Adresse von
stern dort:
.S 134545108 ok
Bei ihnen wird natürlich eine andere Adresse dort stehen, aber es
wird eine Adresse dort stehen. Mit dieser Adresse kann man das Wort
stern auch ausführen, das geht mit
EXECUTE:
EXECUTE * ok
Das Wörtchen ' ist sehr nützlich! Zum einen kann man es
verwenden, um zu testen, ob es ein bestimmtes Wort im Wörterbuch
gibt:
' wasunsinniges ? ok
Es kann durchaus sein, dass ihr Forth sogar noch eine Fehlermeldung
ausgibt, aber auf jeden Fall werden sie das Fragezeichen bekommen.
Aber mit dieser Anwendung ist der Nutzen von ' noch
nicht erschöpft. Ein wirklich wertvoller Nutzen ergibt sich bei der
sogenannten vektoriellen Ausführung.
Was verbirgt sich hinter dem Ausdruck 'Vektorielle Ausführung'? Eigentlich ist es ganz einfach, aber man muss ein bisschen 'um die Ecke' denken. Der Witz liegt darin, dass man die Adresse eines Wortes in eine Variable schreibt. Am einfachsten erklärt sich das mit einem Beispiel.
Nehmen wir an, wir wollten ein Wort definieren, das, passend zur Tageszeit, den richtigen Gruss ausgibt. Morgens soll es 'Guten Morgen', tagsüber 'Guten Tag' und abends 'Guten Abend' ausgeben. Zunächst definiert man die drei Wörter, die den jeweiligen Gruss ausgeben, einzeln:
: MORGEN ." Guten Morgen" ; : TAG ." Guten Tag" ; : ABEND ." Guten Abend" ;
Nun wird eine Variable definiert, die eine der drei Adressen der obigen Worte aufnehmen soll. In Forth hat es sich eingebürgert diese Variablen, die auf eine Routine zeigen mit einem Häkchen als erstes Zeichen des Namens zu markieren. Dieser Tradition wollen wir uns nicht verschließen, also:
VARIABLE 'GRUSS
Nun kann das eigentliche Wort definiert werden, das schließlich zur Anwendung kommen soll. Nach dem vorher gesagten ist es ganz einfach:
: GRUSS 'GRUSS @ EXECUTE ;
Bevor das neue Wort nun ausgeführt werden kann, muss allerdings noch die Zeigervariable gefüllt werden. Wenn sie das nicht tun, können sehr interessante Dinge passieren. Aber das ist nun einfach, wir beginnen mit dem Morgen:
' MORGEN 'GRUSS !
Wird nun GRUSS aufgerufen, dann holt es erst mal die
Adresse aus 'GRUSS, wo jetzt die Adresse von
MORGEN steht, und führt das dann aus. Daher ergibt
sich:
GRUSS Guten Morgen ok
Nun, der Tag zieht sich so dahin. Weil also noch ein bisschen Zeit ist, definieren wir noch ein Wort:
: ES_IST ' 'GRUSS ! ;
Damit ist es dann, so um die Mittagsstunde, möglich zu sagen:
ES_IST TAG ok
Da damit der Inhalt des Zeichers 'GRUSS geändert wird,
ändert sich auch das Verhalten von GRUSS.
GRUSS Guten Tag ok
Das geht übrigens auch mit Worten, die innerhalb einer Definition
stehen. ' sucht ja, wie man gerade gesehen hat
immer die Adresse des nächsten Wortes in der
Eingabe. Will man das gleiche für das nächste Wort in der Definition
erreichen, dann muss man ['] verwenden:
: AUFSTEHEN ['] MORGEN 'GRUSS ! ; : MITTAGESSEN ['] TAG 'GRUSS ! ;
Nun kann man mit einem einfachen AUFSTEHEN sofort dafür
sorgen, dass GRUSS die 'richtige' Ansage macht.
Wofür braucht man die vektorielle Ausführung? Der Hintergrund ist
wieder relativ einfach. Zum Beispiel wird das Wort
NUMBER, das wir später noch genauer kennen lernen
werden, mindestens zwei Definitionen. Einmal die Definition zum
Umgang mit 16 Bit Zahlen und dann die zum Umgang mit 32 Bit Zahlen.
Nun wäre es ausgesprochen mühsam in allen Wörtern, die
NUMBER verwenden jeweils die richtigen Defintionen
anzubringen. Daher ist NUMBER auch ein Wort, dass den
Inhalt einer Variablen ausführt, wie es oben auch GRUSS
gemacht hat.
War das System beim Start auf 16 Bit Zahlen ausgelegt, dann reicht
es einfach den Inhalt der Variablen zu ändern und schon verwenden
alle Worte, die NUMBER verwenden automatisch die
richtigen Definitionen.
Bisher ist immer von der Adresse eines Wortes die Rede gewsen und es wurde dabei eigentlich nicht erklärt, was damit gemeint ist. Das soll (muss) sich nun ändern.
Die Worte, die Forth kennt, stehen alle in einer Liste. Diese Liste ist verkettet, wie man sagt, also kommt man von einem Element der Liste zum nächsten, unabhängig davon, wie lang der Eintrag des Wortes in der Liste ist. So kann die gesamte Liste der Worte durchlaufen werden. Der genaue Aufbau dieser Liste variiert von Forth zu Forth und auch die Reihenfolge der Einträge muss nicht gleich sein, aber dennoch haben alle einen prinzipiell gleichen Aufbau und der soll hier erläutert werden.
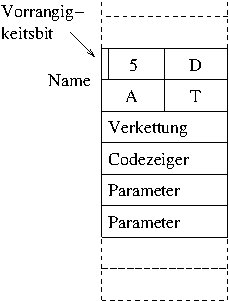
Jeder Eintrag im Wörterbuch, also dieser Liste hat mindestens den Namen des Wortes, eine Verkettung, einen Codezeiger und Parameter.
Bei alten Forth-Systemen wurde der Name nicht
vollständig in der Liste abgespeichert. Meist waren es nur die
ersten drei Buchstaben und dann allerdings noch die Länge des
Wortes. Im obigen Bild ist daher ein Eintrag abgebildet, der ein
Wort beschreibt, das mit DAT anfängt und insgesamt 5
Zeichen lang ist. Die restlichen beiden Buchstaben des Wortes sind
nicht bekannt.
Diese Konvention ist natürlich bei neuen Forth-Systemen längst überholt. Heutzutage können Forth-Worte deutlich längere Namen haben und die werden meist auch vollständig abgespeichert. Im Bild ist zu sehen, dass beim Längenbyte auch noch ein Bit besonders genutzt wird, auch das ist nicht mehr üblich, aber die Funktion, die später noch beschrieben werden wird, gibt es ntürlich noch.
Trotzdem ist es interessant einmal einen solchen 'alten' Eintrag zu
sehen. Er ist zum Beispiel der Grund dafür, dass manche Forth-Wörter
eine etwas eigenwillige Schreibung haben. Ein gutes Beispiel hierfür
sind die Worte DO und ?DO. Hier ist es
zwar nicht relevant, aber bei längeren Wörtern wäre es nicht möglich
sie genau zu identifizieren, wenn der Unterschied in der Schreibung
am Ende erfolgen würde.
Das ebenfalls in jedem Forth-Wörterbucheintrag vorhandete Verkettungsfeld enthält immer die Adresse der vorangegangenen Wortdefinition. Durch dies Verkettungsfeld sind die Einträge miteinander verbunden. Wenn Forth ein neues Wort kompiliert, wird es an die Liste angehängt und in sein Verkettungsfeld die Adresse des bis dahin letzten Wortes geschrieben.
Das erste Wort in der Liste enthält im Verkettungsfeld eine Null.
Daran erkennen ' oder FIND, dass das Ende
der Liste erreicht ist. Wurde ein Wort bis dahin nicht gefunden,
dann steht es nicht im Wörterbuch.
Dann folgt der Codezeiger. Er enthält die Adresse
des Maschinenkodes, der im Fall dieses Wortes auszuführen ist. Bei
einer VARIABLE steht an dieser Stelle zum Beispiel eine
andere Adresse als bei CONSTANT. Eine ausgesprochen
angenehme Eigenschaft von Forth besteht zum Beispiel darin, dass bei
allen VARIABLE der Codezeiger auf die gleich Adresse
zeigen kann. Der Kode muss also nur einmal im Speicher des Computers
vorhanden sein.
Es gibt in Forth einen ganz besonderen Codezeiger, nämlich den, der auf die Doppelpunktdefinition verweist. Dieser Kode sorgt dafür, dass alle Worte, die in einer Doppelpunktdefinition verwendet wurden, der Reihe nach abgearbeitet werden.
Es folgen beliebig viele (auch Null) Parameterfelder. Sie enthalten alle Daten, die das Wort braucht, oder eben die Zeiger auf Worte, die von diesem Wort gebraucht werden (kommt gleich). Es kann aber auch sein, dass dieser Bereich nur aus einem Feld besteht, zum Beispiel bei Variablen und Konstanten einfacher Länge (Bei doppelte Zahlen sind es logischerweise zwei Felder).
Sie wissen ja, dass man mit einer Doppelpunktdefinition den Sprachumfang von Forth erweitern kann. Hier geht es nun endlich darum zu erklären, wie das funktionieren kann und vor allem, wie es Forth damit gelingen kann Programme zu erzeugen, die kürzer sind als entsprechene Programme in Maschinensprache!
Auch hier ist es, wie meist bei Forth, eigentlich recht einfach, dennoch denke ich, dass es vielleicht besser ist, sich mal eine solche Wortdefinition als Beispiel anzusehen. Da es in diesem Zusammenhang auch sinnvoll ist sich anzusehen, wie eine Definition innerhalb einer Definition abgearbeitet wird, sollte man sogar mehr als nur eine Definition betrachten, sondern auch eine Definition, die in einer Definition verwendet wird.
: HAUPTGERICHT SCHNITZEL FRITTEN ; : ESSEN SUPPE HAUPTGERICHT DESSERT ;
Wird nun ESSEN aufgerufen, dann werden der Reihe nach
SUPPE, HAUPTGERICHT und
DESSERT ausgeführt. Danach erfolgt der Aufruf von einem
Forth-Wort, das von dem abschließenden ; in das
Parameterfeld von ESSEN geschrieben wurde. Das
geschieht mit allen Wörtern, die mit einem Doppelpunkt definiert
werden und das Wert, welches das Semikolon in die Liste kompiliert,
heißt EXIT, womit die Nacheinander-Bearbeitung der
einzelnen Einträge in der Liste beendet wird.
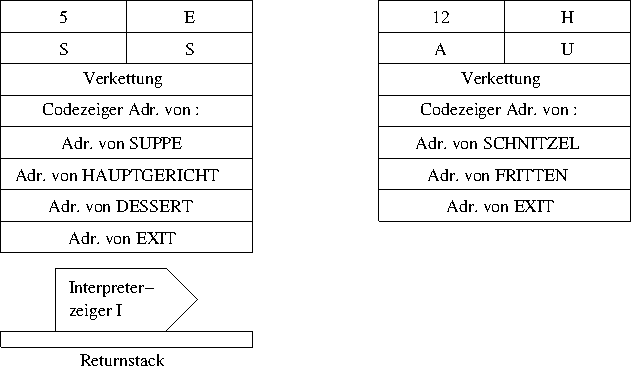
Betrachten wir uns das Ganze mal graphisch; ich denke, dass es dann ziemlich klar werden wir, wie Forth arbeitet. Zuerst mal die beiden Wörter mit ihren Definitionen im Wörterbuch.
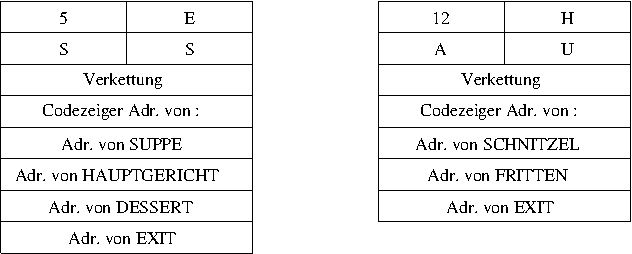
Man kann erkennen, dass beide Einträge von der Struktur her gleich
sind. Der Kopf sollte klar sein und im Parameterfeld steht zunächst
bei beiden ein Zeiger auf die Routine des Doppelpunktwortes. Von
allen weiteren Wörtern stehen nur die Adressen im Eintrag. Es
handelt sich dabei um die gleichen Adressen, die man auch mit
' erhält. EXIT sorgt dafür, dass das
aufrufende Wort weiter ausgeführt wird.
Gehen wir davon aus, dass wir ESSEN aufgerufen haben
und SUPPE gerade beendet ist. Der sogenannte
Interpreterzeiger, I, zeigt nun auf
HAUPTGERICHT.
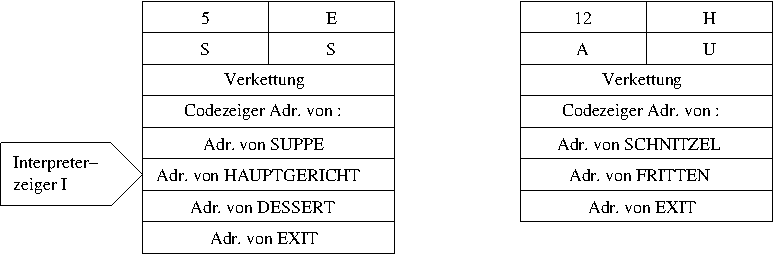
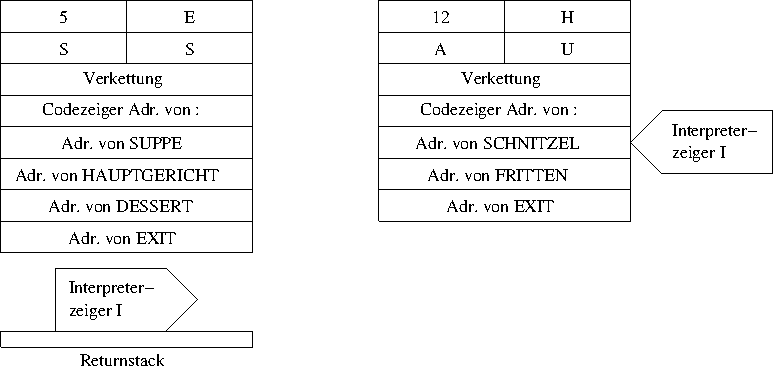
In einem ersten Schritt wird nun der Interpreterzeiger auf die
nächste Adresse erhöht. Das geschieht dazu, dass Forth nach der
Beendigung von HAUPTGERICHT wissen muss, wo es weiter
gehen soll (nämlich mit DESSERT).
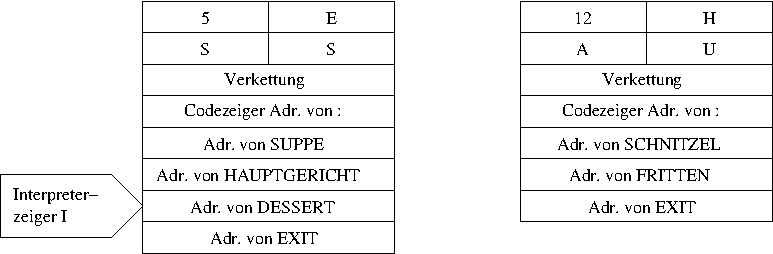
Nun kann die Ausführung von HAUPTGERICHT beginnen. Wie
schon bei ESSEN zeigt die erste Adresse auf die Routine
des Doppelpunktwortes. Diese macht folgendes: Zuerst wird der
Interpreterzeiger auf den Returnstack geschrieben.
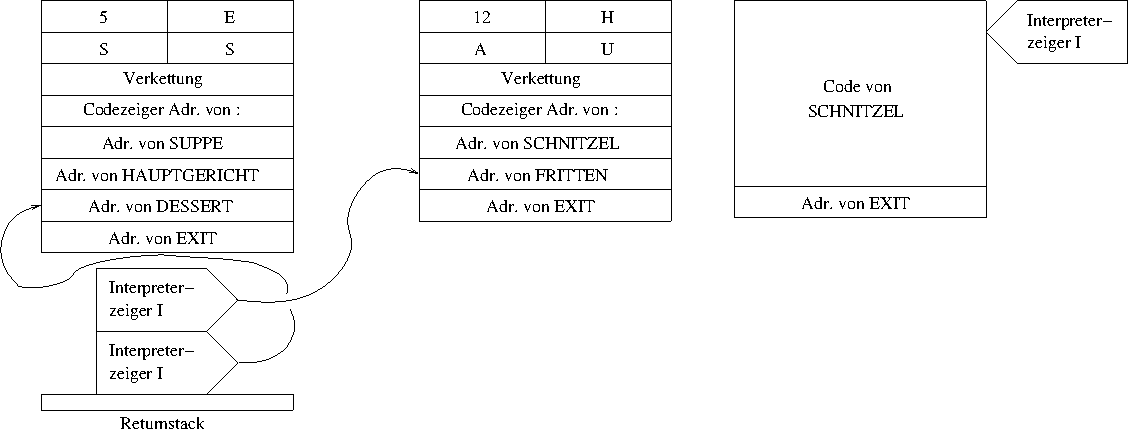
Außerdem schreibt er die Adresse des nächsten Parameters von
HAUPTGERICHT in den Interpreterzeiger, dass ist die
Adresse von SCHNITZEL.
Dort passiert nun wieder das Gleiche. Der Interpreterzeiger wird
erhöht (auf FRITTEN) und dann auf den Returnstack
gelegt und die Ausführung von SCHNITZEL begonnen.
Irgendwann erreicht die Ausführung die Adresse von EXIT
in SCHNITZEL. Hier passiert nun folgendes:
EXIT nimmt einfach die oberste Adresse vom Returnstack
wieder weg und schreibt sie in den Interpreterzeiger. In unserem
Beispiel ist das die Adresse von FRITTEN, was nun
ausgeführt werden kann.
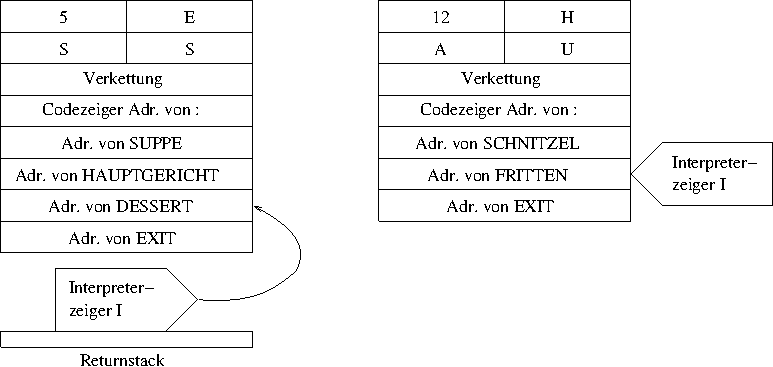
Nun kann FRITTEN ausgeführt werden. Wird da
EXIT erreicht, dann geschieht wieder das Gleiche und
Forth landet bei DESSERT.
Was passiert nun, wenn das letzte Wort abgearbeitet ist? Wohin führt
EXIT dann? Nun, dann kommt einfach das alleroberste
Wort dran und das heißt immer QUIT.
QUIT ist die oberste Ebene des Interpreters. Wird
dieses Wort aufgerufen, dann wird der Returnstack geleert, jede
Kompilierung beendet und der Benutzer kann eine neue Eingabe machen,
die dann interpretiert werden kann. Vereinfacht sieht
QUIT so aus:
: QUIT BEGIN (leere Returnstack) (Eingabe annehmen) INTERPRET ." OK" CR 0 UNTIL ;
Wenn man verstanden hat, wie die Adressinterpretation abläuft, dann
lassen sich damit einige Tricks durchführen. Der einfachste besteht
darin, dass man einfach ein Wort auslassen kann. Dazu muss man nur
EXIT in die Mitte einer Definition schreiben. Wäre
AHUPTGERICHT folgendermaßen definiert:
: HAUPTGERICHT SCHNITZEL EXIT FRITTEN ;
Dann würde FRITTEN nicht erreicht, da der Kode von
EXIT schon vor erreichen des Semikolons ausgeführt
würde. Es geht aber noch besser. Stellen sie sich vor, die
Definitionen sähen folgendermaßen aus:
: HAUPTGERICHT SCHNITZEL FRITTEN R> DROP ; : ESSEN SUPPE HAUPTGERICHT DESSERT ;
Was würde passieren? Nun das R> und das
DROP würden zunächst die oberste Zahl vom Returnstack
auf den Zahlenstack verschieben (R>) und sie dort
löschen (DROP). Damit würde die Adresse von
DESSERT vom Stack verschwunden sein und das nächste
Aufrufen von EXIT würde direkt zum Ende von
ESSEN führen.
Es geht aber noch besser (oder schlimmer, wenn einem die Bezeichnung eher angemessen scheint). Man kann nicht nur eine Adresse vom Stack holen, man kann auch eine andere darauf legen, so dass der Interpreter an einer ganz anderen Stelle weiter macht, als eigentlich gedacht. Man sehe sich die folgenden Definitionen an:
: SUPPE ." Suppe" CR ; : DESSERT ." Dessert" CR ; : PENNEN ." Pennen" CR ; : SCHNITZEL ." Schnitzel" CR ; : FRITTEN ." Fritten" CR ; : HAUPTGERICHT SCHNITZEL FRITTEN R> DROP ['] PENNEN >PHA >R ; : ESSEN SUPPE HAUPTGERICHT DESSERT ;
Eins muss erklärt werden: >PHA ist ein Wort speziell in
lina, womit aus der Adresse, die mit ['] geholt wurde,
die Adresse gemacht werden kann, die der Interpreter erwartet.
Dieses Wort dürfte in anderen Forth-Varianten anders heißen. Spielen
sie ein bisschen mit ihrem Forth rum, sie werden es finden.
Interessant wird es nun, wenn wir ESSEN aufrufen:
ESSEN
Suppe
Schnitzel
Fritten
Pennen
OK
Und schon wurde aus unserem ESSEN etwas, was in seiner
Definition gar nicht vorkommt!
Ich möchte an dieser Stelle auf zwei Aspekte aufmerksam machen: 1.
ist das Auslassen von Wortteilen, die man durch einkompilieren von
EXIT oder dem Entfernen einer Adresse vom Returnstack
erreicht sicherlich nur innerhalb einer IF ... ELSE ...
THEN Umgebung sinnvoll. Es kann auf diese Art auf eine
besondere Situation reagiert werden. Das Einkompilieren von
EXIT im Hauptgericht könnte zum Beispiel darauf
reagieren, wenn man nach dem Essen des Schnitzels schon satt ist und
die Fritten nicht mehr will.
Noch mehr Vorsicht sollte man bei der Manipulation vom Returnstack in der zuletzt gezeigten Variante üben! Genauer gesagt würde ich solche Programmiertechniken ganz lassen. Der Sourcekode wird extrem unlesbar und die Effekte, die man damit erreicht lassen sich auf elegantere Art auch lösen, ohne dass man zu solchen Tricks greifen muss.
Bisher ist immer von dem Wörterbuch die Rede gewesen. Das ist insofern richtig, als es in der Tat nur ein Wörterbuch gibt. Dieses Wörterbuch ist allerdings in verschiedene Vokabulare unterteilt. Der Sinn dafür liegt darin, dass man so in bestimmten Umgebungen dafür sorgen kann, dass Worte erneut definiert werden können, in dieser Umgebung aber eine andere Bedeutung haben, als in einem anderen Vokabular.
In manchen, vor allem älteren Forth-Varianten gab es zum Beispiel
einen Editor. Häufig war es dann so, dass das Wort I,
das im normalen Vokabular (Genannt: FORTH) die
Bedeutung hat, den obersten Wert auf dem Returnstack auf den
Zahlenstack zu kopieren, im Editor die Bedeutung einer Einfügung
hatte (I wie Insert).
Ein weiterer Vorteil der Vokabulare liegt in der Geschwindigkeit. Dies gilt insbesondere für neuere Varianten von Forth, die mit Vokabularen etwas anders umgehen, als alte Forth-Varianten. Um das erklären zu können, sollte man sich ansehen, wie das Wörterbuch aufgebaut und in unterschiedliche Vokabulare unterteilt ist.
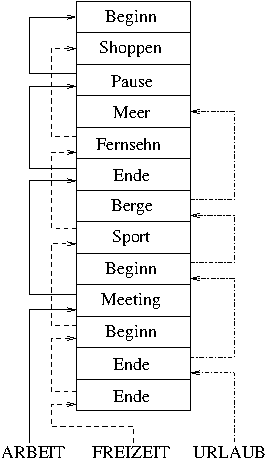
Dargestellt sind die drei (fiktiven) Vokabulare ARBEIT, FREIZEIT und URLAUB. Man kann einerseits erkennen, dass z.B. alle drei Vokabulare die Wörter BEGINN und ENDE enthalten, aber in allen drei Vokabularen bedeuten sie etwas anderes. Der Geschwindigkeitsvorteil wird auch erkennbar. Wenn bei einem solchen Forth-System etwas eingegeben wird, dann muss nicht das gesamte Wörterbuch durchsucht werden, sondern nur das jeweils aktuelle und damit wesentlich weniger Worte. Bei modernen Forth-Varianten ist der Vorteil deshalb noch größer, weil meist eine Suchreihenfolge angegeben werden kann. Das heißt, wenn in dem aktuellen Vokabular nichts gefunden wird, dann kann es immer noch andere Vokabulare geben, in denen das gesuchte Wort steht. Man kann also mehrere Vokabulare gleichzeitig nutzen, aber dennoch den Vorteil der Geschwindigkeit und der unterschiedlichen Bedeutungen behalten, da immer das zuerst gefundene Wort verwendet wird.
Der Umgang mit Vokabularen in Forth ist sehr einfach. Beim Start ist
immer FORTH das aktuelle Vokabular, sowohl hinsichtlich
der Suche als auch hinsichtlich des Vokabulars an das neue Worte
angehängt werden. Es gibt nun einige Wörter, die das Vokabular
ändern. Ein solches Wort ist das Wort ASSEMBLER, auf
das hier nicht weiter eingegangen wird, außer dass es eben auf das
Assembler-Vokabular umschaltet. Umschalten meint hier, dass Wörter
(erst) in diesem Vokabular gesucht werden.
Will man erreichen, dass neue Worte auch an dieses Vokabular
angehängt werden, muss man das Wort DEFINITIONS
verwenden. Es wird zusammen mit einem Vokabularnamen aufgerufen und
sorgt so dafür, dass neue Definitionen an dieses benannte Vokabular
angehängt werden.
Will man erreichen, dass alles wieder 'beim Alten' ist, braucht man
nur einzugeben: FORTH DEFINITIONS.
Der letzte Abschnitt hat auch gezeigt, dass Forth mit Variablen arbeitet. Dabei werden grundsätzlich sogenannte Benutzer- oder User-Variablen von Systemvariablen unterschieden. Die Systemvariablen sind in der Regel nicht so interessant, werden aber vom gesamten System verwendet. Anders ist das bei den Benutzervariablen. Insbesondere bei Mehrplatzsystemen, gibt es für jeden Benutzer von Forth einen eigenen Satz an Benutzervariablen.
Die Variablen CONTEXT und CURRENT sind
solche Benutzervariablen. CONTEXT zeigt auf das
Vokabular, in dem zur Zeit als erstes gesucht werden soll und
CURRENT auf das, an das neue Worte angehängt werden
sollen.
Es gibt aber noch ein paar weitere Benutzervariablen, die
interessant sind. Da ist zum einen S0. Das ist ein
Zeiger auf den 'Boden' des Zahlenstacks. Dieser Wert ist daher so
interessant, das bei vielen Forth-Sytemen der Boden des Zahlenstacks
zugleich der Anfang des Eingabepuffers ist.
Eine weitere interessante Benutzervariable ist BASE.
Sie enthält die Zahlenbasis, mit der Forth gerade Zahlen versteht
und auch ausgibt. Damit sind dann auch noch andere Zahlensystem als
nur das dezimale oder hexadezimale möglich.
Interessiert man sich für den binären Aufbau einer Zahl, dann kann man zum Beispiel 2 als Zahlenbasis verwenden. Das folgende Beispiel zeigt es:
153 OK 2 BASE ! . 10011001 OK DECIMAL OK
Auch ganz witzig ist die Zahlenbasis 36. Da 'oberhalb' der Ziffer '9' die Buchstaben verwendet werden, deckt man mit dieser Zahlenbasis alle 26 Buchstaben ab. Man kann damit dann untersuchen, welche dezimale Entsprechung der eigene Name hat (Wenn er nicht zu lang ist):
36 BASE ! OK FRITZ OK DECIMAL OK . 26478359 OK